2023AIWIN——中文网页自动导航挑战赛
主办方: 中国太平洋保险集团 - 当前服务器时间 十二月 21, 2025, 9:17 a.m. UTC+8
奖励 ¥120000
参赛提交
奖励 ¥120000
上一阶段
终选答辩阶段五月 29, 2023, 午夜 UTC+8
当前阶段
A榜四月 18, 2023, 8 a.m. UTC+8
终止阶段
Competition Ends七月 31, 2023, 8 a.m. UTC+8
AIWIN--中文网页自动导航挑战赛
0530 公告
本次截止B榜后,按榜单排名顺位,及分数有效性(是否有A榜分数、团队是否全员实名),确定如下团队进入复核范围:
1 Z Lab
2 YDDM
3 nicolas
4 人人都是神经元
5 天选之人
6 代码写不队
7 GPT5.0项目组
8 三块一大碗
9 newboy
10 JoKer47
11 逢考必过
12 libra
13 西莓队
14 nnnn01
15 jy2211
16 ALEX
17 DataMiner
18 人工智障
19 Elden Lord
21 AI_RZ
其中排位20位的SYT团队,因未全员实名,遗憾失去资格。
特此公告
0528 公告
各位请注意,今晚24点,将关闭B榜提交。请大家注意好时间,及时提交。
另,再次提醒务必所在团队的所有成员都完成实名认证,成绩方生效。请记得在29日17点前完成实名认证。
0525 公告
1. A榜今晚24点截止
请各位选手注意提交截止时间,并记得做好实名认证,以使A榜成绩生效。B榜将在今晚24点A榜截止后开启,并提供数据下载。
2. 数据内容修正
针对一些选手反馈的个别网页中存在部分指令对应的元素内容缺失、混乱或不一致的问题,现已对数据做了内容修正,内容修正说明如下:
(a) 修正了“中国银行保险监督管理委员会”网页中个别指令的地址缺失、监管机构混乱的情况
(b).修正了截止时间,统一为“2023-03-15”
基于内容修正,下述文件已发生更新,请选手下载更新:
(a) 训练集 (已更新A榜阶段数据集至0525版本,内包含训练集和A榜测试集)
(b) A榜测试集(同上)
(c) 基于B榜新数据结构的A榜测试集(作为参考示例)(已更新至0525版本)
同时,线上评分的真值也做了对应修改。
注:请注意A榜本身的分数仅作为参考,并不作为最终评审的依据。
0524公告
选手们,基于昨日0523公告,大家应该已获悉在B榜时,测试集的数据结构将从现有A榜的“单条待测指令+kv对”
变化为B榜的“整个网页的节点+所有待测指令+节点映射表“(具体变化请见线上0523公告)。
我们也听到了选手们对此变化的反馈和建议,经过和命题方中国太保沟通,现在发布一个新的A榜测试集:它基于B榜数据结构,将原有A榜测试集调整为了nodename和node_map数据的形式,作为参考。将要发布的B榜测试集与其的区别只在于每个网页的"instruction"字段(A榜30条/网页,B榜50条/网页)。此外nodename是指查询指令涉及的所有节点,不包含指令无关节点(如登录、返回等)。
请大家及时下载该数据集(参赛提交-获取数据-2023S-T1太保-新数据结构A榜测试集(供B榜前参照)),可提前在A榜阶段对解决方案进行调整和优化。
注: A榜当前的输入输出均未发生改变,仅未来B榜的输入改变,但输出未变。现在发布的这个新A榜测试集只是为大家提前提供一个示例用于熟悉B榜测试集,和优化当前模型。
0523公告
各位“中文网页自动导航挑战赛”的选手:
1. A榜即将在26日凌晨0点(25日午夜24点)关闭
请抓紧时间做好A榜提交,并请记得做好实名认证。实名认证需团队所有成员均完成才行。
2. B榜数据较A榜数据变化的预告
请注意B榜数据的结构上,将较A榜数据发生如下变化:
【以”中国裁判文书网“为例,给出数据示例】
A榜:单条待测指令+kv对
[
{
"page_source": "中国裁判文书网",
"instruction_detail": [
{
"instruction": "请检索关于建设银行的2018年1月1日到2023年3月1日的湖南省高级人民法院的决定书",
"key-value": {
"全文检索": "建设银行",
"法院名称": "湖南省高级人民法院",
"裁判日期_1": "2018-01-01",
"裁判日期_2": "2023-03-01",
"文书类型": "决定书"
}
}
],
},
...
]
B榜:整个网页的节点+所有待测指令+节点映射表
[
{
"page_source": "中国裁判文书网",
"node_name": [
"起始日期",
"检索",
"高级检索",
"案件类型",
"全文检索",
"审判程序",
"当事人",
"法院名称",
"文书类型",
"审判人员",
"律师",
"案由",
"截止日期"
],
"instruction": [
"请检索关于建设银行的2018年1月1日到2023年3月1日的湖南省高级人民法院的决定书",
"请搜索最近五个月的决定书",
"请搜索:北京市第一中级人民法院的通知书",
...,
],
"node_map": {
"起始日期": "裁判日期_1",
"截止日期": "裁判日期_2"
},
...
]
即B榜测试集的结构将由以下元素构成:
-- page_source:页面名称
-- node_name :页面dom节点名称 (请注意下拉框选项和导航树下拉框选项的内容需要在指令中抽取,在nodename中不包含)
-- instruction :待测指令
-- node_map :节点映射
node_map用于将最终结果中的节点名称,进行映射,以便计算SR;若node_map为空,则无需映射
node_map用法示例
* 指令:请搜索最近五个月的决定书
* 预测序列 :
"截止日期": {
"dom_type": "日期输入框",
"value": "2023-03-15",
"action": "输入"
}
* 根据node_map:
"node_map": {
"起始日期": "裁判日期_1",
"截止日期": "裁判日期_2"
}
* 序列转化后:
"裁判日期_2": {
"dom_type": "日期输入框",
"value": "2023-03-15",
"action": "输入"
}
最终提交结果前,需将节点名做映射
注:选手在具体方案中需遍历待映射节点,此处示例只提供一条供参考
3. B榜时长从48小时将延长至72小时
考虑到数据的变化,B榜时长将从48小时,延长至72小时,即将在5月28日午夜24点截止(29日凌晨0点)
0513 公告
根据命题方的最新通知,对当前A榜阶段提供的数据集的指令文件予以更新。
1.更新理由:
之前在个别网页的kv对里,没有提供除了“查询”之外的按钮,如“12306”等,所以更新了instruction文件
2.更新补丁:
更新了instrcution_trainset.json和instruction_testA.json两个文件
对于已下载数据的同学,可选择直接下载仅更新的文件:
文件直接下载链接: https://pan.baidu.com/s/1kvOqaEJ5N5RPATNgV2WgNA?pwd=361a
对于新参赛的同学,稍后可直接在数据页面下载0513版(V3版)的数据,内含上述两个更新文件。
3.其他影响:
不影响其他内容,标签数据无误,未更改。
0505 公告
1. 经和命题方沟通讨论后,确定当前赛题解决方案方法上不做严格限制,鼓励大家采用各类合理的方法完成解题。但应尽可能探索解决方案的通用性,特别是解决方案对复杂、陌生网页的处理能力。
2. 经过A、B榜两轮线上竞赛后,按B榜成绩将要求前20名选手提交解决方案和代码。命题方保留权利基于解决方案的通用性、创新性等因素而非绝对的线上排名来确定最终的晋级10强。
0423 公告
- 请各位选手注意,当前已更新数据集到V2版本,请务必更新:
1. 更新了其中“仿真页面”的“安居客”页面,删除了一个干扰按钮
2. 更新了“相关脚本”中的selenium_run.py,增加了注释
- 针对选手关心的A榜测试集含有Key-Value对的问题,命题方明确这仅在A榜期间提供,是为了一定程度降低难度;B榜期间将仅有Key值(此处指将提供整个网页的节点+所有待测指令+节点映射表值,但单条指令不再单独提供kv对)。请同时注意B榜周期仅72小时。
赛题综述
|
|
说明 |
|
训练集 |
20个仿真网页,覆盖金融、法律、医疗、教育、交通、电商类(购票、订餐、购物、出行等)等多个领域,每个网页包含120条指令,共2400条指令 |
|
测试集 |
1600条自然语言指令数据,具体包含共20个网页,每个网页包含80条指令,分A/B榜,A榜30条,B榜50条(指令总量为A榜600+B榜1000) |
|
开发与模型输出 |
可线下开发和模型输出,AIWIN平台提交结果 |
|
关键节点(拟) |
本竞赛采用AB榜模式开展: A榜开启:4月18日 A榜截止:5月25日24:00 (请务必完成实名认证) B榜开启:5月26日00:00(必须在A榜有成绩方 取得B榜提交资格) B榜截止:5月28日24:00 解决方案PPT提交截止:5月30日24:00 |
|
提交限制 |
A榜每日最多3次提交; B榜全程最多5次提交 |
|
奖励 |
依据: 赛事将以B榜分数为准计算技术得分,并综合解决方案的原创性和创意性,最终选拔10名晋级决赛答辩。决赛答辩将通过现场评审得分结合技术得分做综合考量。 奖励: 1.12万元奖金池 2.太保实习绿色直通车(晋级前30名的同学可优先考虑参与太保的实训带教或实习,细则待公布) 3.AIWIN证书 |
竞赛详细文案
一. 赛题考官
中国太平洋保险集团有限责任公司
二. 赛事背景
RPA(Robotic Process Automation),即机器人流程自动化。通过模仿人的方式在电脑上执行一系列操作,可以实现人在电脑上的所有操作行为,如复制、粘贴、数据录入、网页导航、打开、关闭等,并且可以按照一定的规则持续不断地重复操作。
在具体的操作层面上,可以打开邮件、下载附件、登录网站和系统、读取数据库、移动文件和文件夹、复制粘贴、写入表格数据、网页数据抓取、文档数据抓取、连接系统API等。
传统的网页流程自动导航任务,通过熟练的业务人员配置低代码工具提供的原子能力,完成一整套规则化流程。该方案只能解决某一单一网页下具有固定操作步骤的流程,当网页发生变化或任务发生变化时,已有配置流程无法使用,需要重新配置新的流程。随着业务需求的增加,不仅需要有专业背景的人员维护,同时,流程繁琐的配置方式问题也凸显。针对上述问题,一种可迁移至相同场景不同流程的自动化导航技术亟待研究。
二. 赛事任务
网页自动导航任务:根据用户输入的自然语言指令,在网页中规划(输出)一条动作序列,自动化完成指令中包含的用户意图
根据指令意图与网页(网页中可能包含公告、提示等异常弹窗)功能的不同,分有不同的任务,常见的任务包括:检索、下载、收藏 、评论等。本赛题仅涉及信息检索任务,涉及的原子操作包括:输入框、下拉框、单选框、复选框、日期选择、导航树 、按钮。根据原子操作的数量与难度,可将任务指令按如下难度划分:
-
单原子指令:只包含1个原子操作的自然语言指令
-
多原子指令:包含2个及以上原子操作的自然语言指令
-
其中,大于等于5个原子操作的自然语言指令属于长程规划指令
-
其中,少于5个原子操作的自然语言指令属于短程规划指令
-
本次赛题为探索多场景下指令检索任务,主要考察多场景指令任务迁移能力,操作序列不得使用规则或标注生成,比赛提交结果的模型为端到端模型或pipeline级联模型,不对模型集成方案进行考察。
注: 0505公告: 经和命题方沟通讨论后,确定当前赛题解决方案方法上不做严格限制,鼓励大家采用各类合理的方法完成解题。但应尽可能探索解决方案的通用性,特别是解决方案对复杂、陌生网页的处理能力。
三. 赛题数据
数据说明
-
数据领域:
-
金融、法律、医疗、教育、交通等领域网页数据,包含:巨潮资讯、中国人民银行、上交所、中国证券投资基金业协会、中国银行保险监督管理委员会、裁判文书网、中国法律服务网、卫健委信用信息网(医生信息查询、护士信息查询)、学信网、交通安全综合服务管理平台、企查查、国家企业信用信息公示系统、国家统计局,共14个网页
-
电商领域(购票、订餐、购物、出行等)网页数据,包含:猫眼电影、qq音乐、顺丰快递(查运费时效、查收寄标准)、火车票12306、安居客
-
-
每个领域收集6~15个不同页面,两个领域共包含20个网页 ,A榜每个网页提供150条不同的指令(指令涵盖不同的任务),包含训练集与测试集,其中,每个网页包含训练集120条,测试集30条;B榜每个网页提供50条不同的指令,仅包含测试集
-
基本动作集包含:点击(click)、输入(type)
-
专家演示:赛事组提供一个网页“巨潮资讯”的数据作为示例,并给出采集专家演示数据的工具使用说明,选手可根据需要自行创建额外的专家演示数据(具体见2.b节的说明)
-
允许参赛者使用公开的预训练模型和公开、自建数据的训练集,但需要提交明确的清单(具体参见第五节中关于解题文档PPT的说明)
2. 数据及相关内容说明
a. 输入/输出示例
(1)输入:一段自然语言指令(或槽位指令)与仿真页面
举例:

-
"instruction"为自然语言指令
-
"key-value"为槽位指令,key为操作节点的文本描述、value为操作值
- 指令中存在类似“几年之内”“最近几个月”等表述,统一认为结束日期是2023年3月15日。如“最近一年”表示“2022年3月15日到2023年3月15日”。

注:如果网页中两个节点对应同一个描述key时,其中一个描述为“key_1”,另一个描述为“key_2”。例如上图网页中与“裁判日期”相对应的有两个输入框,两个框的描述分别为“裁判日期_1”和“裁判日期_2”。
(2)输出:动作流程序列集
举例:
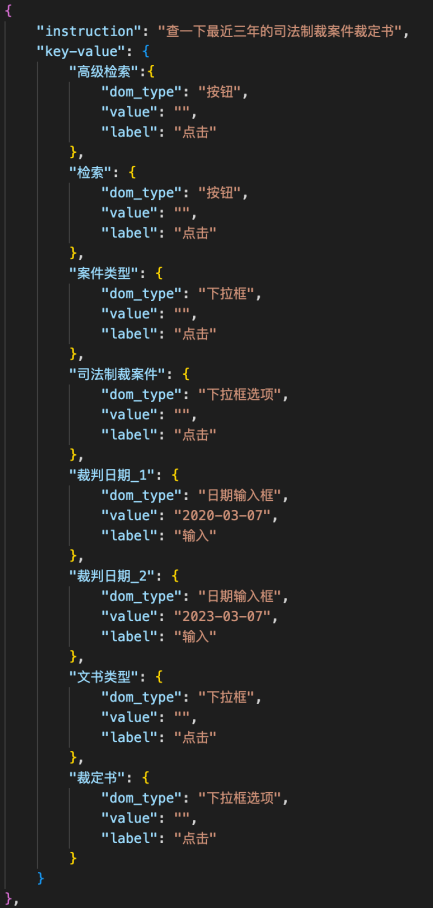
"instruction"为任务指令的自然语言形式,"key-value"为任务指令的槽位形式,key为操作节点的文本描述,dom_type为操作节点类别(DOM元素类别见“奖励函数(可选)”一节说明),value为操作值,action为动作。
说明:在执行过程中,根据所采用技术方案的不同,输出示例的形式或顺序都可能不唯一。因此,上述示例顺序只做参考。
b. 专家演示数据(可选)
模仿学习是指从专家演示提供的范例中进行有监督学习,使模型学习到一个较好的初始化策略。BC_generate.zip(请见比赛数据包——BC数据)中包含:
-
instruction文件夹:存放自然指令
-
page文件夹:存放仿真页面
-
result文件夹:存放专家演示数据的结果
-
bc_generate.py:BC录制脚本
-
readme.md :录制说明文档(详细的使用步骤、其余文件的说明)
c. 奖励函数(可选)
奖励函数(请见比赛数据包——相关脚本——build_reward.py)作为指令任务是否完成的判断。仅针对本竞赛涉及的“信息检索“任务,奖励函数的构建涉及可操作DOM元素(DOM tree中叶子结点)的描述和类别信息。
Reward计算方式:
-
条件一:序列包含检索触发按钮(如“中国裁判文书网”的检索按钮为“检索”)
-
条件二:除了按钮之外的其余操作,与标签操作序列相同
满足上述两个条件,则reward值为1,指令任务完成标志为True;否则值分别为0和False。
DOM元素类别包含:链接、输入框、下拉框、下拉框选项、单选框、复选框、按钮、日期输入框、日期下拉框(日期没有下拉选择和跳转,统一为“日期输入框”节点进行操作)、导航树下拉框(导航树扩展按钮和导航树选项,统一为“导航树下拉框选项”单个节点进行操作)
|
链接 |
输入框 |
下拉框 |
下拉框选项 |
单选框 |

|

|

|

|

|
|
复选框 |
按钮 |
日期输入框 |
日期选择 |
导航树 |

|

|

|

|

|
d. 仿真网页打开方式
仿真网页打开方式有3种:
-
根目录存在**.html文件:根据readme.md,直接点开对应html文件(如猫眼、qq音乐等);
-
根目录存在static-server.js文件:在根目录下进入终端,输入“node static-server.js”获取地址和端口,根据readme.md地址在浏览器中打开网页;
-
根目录不存在static-server.js文件:在根目录下进入终端,输入“serve”获取地址和端口,根据readme.md地址在浏览器中打开网页。
【注意】打开网页之前需配置node.js
node.js安装方法:
-
在官网下载https://nodejs.org/en/download/
-
terminal输入:npm i -g serve
-
在开发好网页的文件夹下输入serve,验证是否安装成功
e. 页面操作可视化(动作序列验证的方法)
对于模型产出的动作序列结果,我们可以通过第三方插件Selenium控制仿真网页,实现页面操作可视化从而对结果验证。Selenium通过使用WebDriver支持市场上所有主流浏览器的自动化。Webdriver 是一个 API 和协议,它定义了一个语言中立的接口,用于控制 web 浏览器的行为。selenium_run.py脚本(请见比赛数据包——相关脚本——selenium_run.py)给出使用Selenium控制chrome浏览器的示例。
四. 评审规则
1. 评估指标
本次比赛以测试集中所有指令的成功率(successful rate, SR)作为评价指标。
线上任务A/B榜采用统一的评价指标,具体指标如下:
-
预测操作结果:Predictions
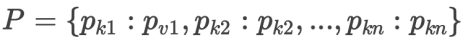
-
标准操作结果:Groundtruth
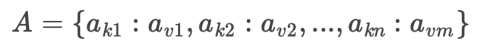
-
单条指令成功率计算指标:
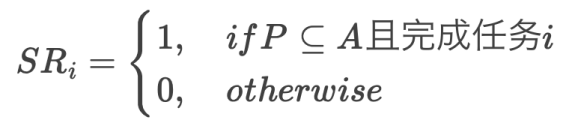
,其中i表示第i条指令的计算结果
最终总分计算公式如下:
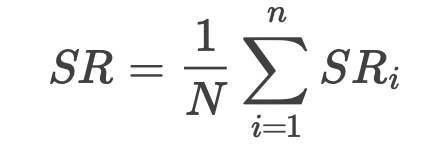
截屏2023-04-03 02.21.16
,其中N为测试集中包含指令总数。
注意:由于采取方案的不同,完成任务的操作流程和顺序存在差异,单条指标计算以任务完成为目标,任务完成,成功率则为1。
2. 评测及排行
-
本赛题均提供下载数据,选手在本地进行算法调试,在比赛页面提交结果
-
本次比赛分A、B榜,两个榜单采用相同的评价指标,排行按照B榜得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名
3.终选方式
排行榜更新结束后,前20名参赛团队需要将模型的源代码、说明文档(PPT)全部提交,进行模型和结果真实性验证。命题方将对提交的文档、 源代码做检视,并最终结合B榜成绩,选取10名队伍晋级最终现场答辩。
综合选手现场答辩、线上排名分数以及其他命题方设定的综合维度(如模型思路创新性都能够),确定最后的综合排名。
五. 赛程规则及作品提交要求
本赛题下的线上比赛将设定为两个时间上递进进行的任务。
1.线上比赛
本赛题下的线上比赛将设定为两个榜单指令泛化的任务。
该阶段内接受个人报名、团队登记(报名登记规则请详细阅读比赛规则)
团队创建需经管理员审核(若正式代表某机构或企业参赛,需机构或企业出具相应盖章函件证明方可建立)。
A.赛程说明:
(1)本赛题主任务分为A/B榜,在4月18日正式开启。B榜排名前20的有效选手需提交解题思路PPT和代码(具体待邮件通知)。解题思路PPT命名应为选手名.ppt,对于个人参赛选手名即个人ID,团队参赛选手名即为团队名。
(2)解题思路PPT需包含以下内容:
-
个人简介:在职者填写当前职业和在职机构(如方便透露),在校者请填写当前年级、专业、高校团队简介:团队整体介绍,以及每个成员的介绍、成员分工
-
赛题理解与问题建模:清楚描述对赛题任务的理解,抽象为模型建立的策略
-
数据探索与特征工程:针对赛题提供的数据描述必要的数据特征、数据清洗、特征工程的关键思路和方法
-
模型训练和融合:描述模型的训练、实验对比和融合过程与方法
-
代码依赖环境:详细列出包括整体建模采用的基础框架(含版本号)以及依赖的包等
-
代码运行说明:对如何运行代码予以充分说明
(3)赛题A榜和B榜采用统一训练集,训练集为20个网页的2400条指令;A榜测试集为20个网页的600条指令,B榜为20个网页的1000条指令。
相关数据集请在「参赛提交」——「下载」下予以下载,A榜时仅开放训练集和A榜测试集,B榜时提供所有数据集。
和A榜测试集,B榜时提供所有数据集。
(4)A榜:4月18日开启,5月25日24点关闭
B榜:5月26日0点自动切换开启,5月27日24点关闭
(5)建议B榜排名前30范围内的选手都做好相应PPT的准备,组委会将在28日内对排行榜做检视确定有效选手(须有A榜成绩、须实名认证、排除重复账号等),并通知任何递补进入有效前20范围的选手补交PPT。排行榜上排名在1-20内的队伍应在截止日前先主动提交PPT。
B.结果提交的内容和要求:
AIWIN平台(ailab.aiwin.org.cn)要求所有提交内容统一打包为zip文件上传(请参见「参赛提交」tab下「下载」板块提供的提交样例),其内包含:
模型输入测试集后输出的结果文件,文件格式统一为json,名称必须统一为submission.json,
该json文件应封装入一个ZIP包,ZIP建议命名为 ID_YYMMDD.zip,用户 ID 为你注册时的用户名。
json内的数据格式:对于单个页面的预测结果,其结构如下:

其中,"page_source"为网页名称,"instruction_detail"包含一个网页中的所有任务指令,每一条任务指令的key为操作节点的文本描述,dom_type为操作节点类别,value为操作值,action为预测的动作。
将多个页面的预测结果放到一个list中(格式和训练集标签文件保持一致)。
C.提交规则:
(1)A榜设定每日最多3次提交,选手需在5月25日24:00前完成提交
(2)B榜设定B榜总赛程最多5次提交,选手需在5月27日24:00前完成提交
六. 相关技术参考
6.1 参考思路
赛题解决方案参考如下:

我们的数据源为网页和自然语言指令,需要选手:
1. 对网页进行DOM解析,得到DOM元素的分类和描述绑定(如网页“巨潮网络”中,结点“债券”的DOM类型为“按钮”,结点“分类”的DOM类型为“下拉框”)

2. 采用大语言模型(Large Language Models,LLM)或者强化学习(Reinforcement Learning, RL)的方式进行决策规划,得到操作序列
【注意】决策模型输出的序列格式,需要和训练集标签格式保持一致,即每个操作节点包含:dom_type、value、action三个属性。
**请注意,再次强调最终方案不能通过规则实现**
(注: 0505公告:经和命题方沟通讨论后,确定当前赛题解决方案方法上不做严格限制,鼓励大家采用各类合理的方法完成解题。但应尽可能探索解决方案的通用性,特别是解决方案对复杂、陌生网页的处理能力。)
按照上述提供的技术方案思路,可进一步拆解为两步实现解决防范:
1. 可使用“playwright+大语言模型”方式进行网页DOM解析(BC_generate文件夹中包含playwright大致介绍);
2. 大语言模型或者强化学习的方式进行指令理解与决策规划
注:允许使用现有开源大语言模型
6.2 参考资料
-
DOM解析相关
-
Mapping natural language commands to web elements
-
Self-Supervised Learning of the UI Language
-
UNDERSTANDING HTML WITH LARGE LANGUAGE MODELS
-
Decision Transformers与RL相关
-
World of Bits An Open-Domain Platform for Web-Based Agents
-
DOM-Q-NET-GROUNDED RL ON STRUCTURED LANGUAGE
-
A data-driven approach for learning to control computers
-
LEARNING TO NAVIGATE THE WEB
-
REINFORCEMENT LEARNING ON WEB INTERFACES USING WORKFLOW-GUIDED EXPLORATION
-
Decision Transformer-Reinforcement Learning via Sequence Modeling
-
Online Decision Transformer
-
IN-CONTEXT REINFORCEMENT LEARNING WITH ALGORITHM DISTILLATION
-
Multi-game decision transformers
-
Reinforcement learning via sequence modeling
-
Large Language Model相关
-
Language Models are Few-Shot Learners
-
Training language models to follow instructions with human feedback
-
ChatGPT for Robotics: Design Principles and Model Abilities
七. 赛事奖励
1. 赛事奖金与奖励
|
类型 |
奖项 |
名次 |
奖励(税前) |
|
竞赛奖励 (依据综合排名 = B 榜排名 + 复审结果 + 终选答辩排名) |
一等奖 |
第1名 |
60000 元 |
|
二等奖 |
第2名 |
20000 元 |
|
|
三等奖 |
第 3 名 |
10000 元 |
|
|
四等奖 |
第 4-6 名 |
6000 元 |
|
|
五等奖 |
第 7-10 名 |
3000 元 |
注:
- 组委会对上述奖励方案享有最终解释权和调整权
- 以上奖金金额为税前金额,奖项获得者需承担个人所得税 20%
2. 证书
所有获奖选手(含学习奖励奖项与竞赛奖励奖项)将颁发盖有“世界人工智能创新大赛组委会”的赛事证书,对应赛题的证书上将同时印刻有赛事命题方的官方 logo
3.实习生绿色直通车
对于赛事排名靠前的选手将给予实习生绿色直通车的机会,将在实习招聘过程中给予一定优惠(如免笔试等,具体待进一步确定)
1. 评估指标
本次比赛以测试集中所有指令的成功率(successful rate, SR)作为评价指标。
线上任务A/B榜采用统一的评价指标,具体指标如下:
-
预测操作结果:Predictions
-
标准操作结果:Groundtruth
-
单条指令成功率计算指标:
,其中i表示第i条指令的计算结果
最终总分计算公式如下:
截屏2023-04-03 02.21.16
,其中N为测试集中包含指令总数。
注意:由于采取方案的不同,完成任务的操作流程和顺序存在差异,单条指标计算以任务完成为目标,任务完成,成功率则为1。
2. 评测及排行
-
本赛题均提供下载数据,选手在本地进行算法调试,在比赛页面提交结果
-
本次比赛分A、B榜,两个榜单采用相同的评价指标,排行按照B榜得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名
3.终选方式
排行榜更新结束后,前20名参赛团队需要将模型的源代码、说明文档(PPT)全部提交,进行模型和结果真实性验证。命题方将对提交的文档、 源代码做检视,并最终结合B榜成绩,选取10名队伍晋级最终现场答辩。
综合选手现场答辩、线上排名分数以及其他命题方设定的综合维度(如模型思路创新性都能够),确定最后的综合排名。
赛事规则
- 参赛人群:大赛面向社会各界开放,不限年龄国籍,高校、科研院所、企业从业人员均可报名参赛。参与大赛组织工作有关单位员工及直系亲属可参赛但不可获奖;
- 账号体系:赛事平台的账号体系以个人为单位,注册平台需要提交个人的姓名、学校/单位、邮箱、手机等信息。上述信息仅用于赛事联络和运营。
- 赛事报名:赛题报名以单个账号为单位开展。选手根据自身情况,仅可二选一选择一种身份参赛:
- 个人参赛:选手以个人身份注册账号直接参赛
- 团队参赛:团队的每个成员均需在比赛平台注册,并通过系统在所参与的赛题上组建团队,并将各队员添加入团队作为成员。每个团队最多 5 人。 团队成员在加入团队后,各自可代表团队提交项目,且团队成员个人成绩(无论成团前后)将被统一视为团队成绩,团队成绩最终成绩取团队各成员所取得的最好成绩。同一团队仅可占 1 席晋级名额和奖项名额,如遇同一团队多名成员占有 1 席以上晋级范围的排名,则名额顺延至下一团队或个人。
- 作品提交:作品提交规则按各赛道设定执行。作品提交由单个个人账号执行。参赛作品必须保证原创性,不违反任何中华人民共和国的有关法律,不侵犯任何第三方知识产权或者其他权利;一经发现或经权利人提出并查证,组委会将取消其比赛成绩并进行严肃处理;
- 排行规则:排行榜以个人账号为单位,依据所提交的结果评分予以排名。如个人账号从属于某团队,则排行榜在该个人账号旁会显示其团队名称。团队的排名以团队中各团队成员的最高排名为准。
- 排名验证:赛题出题方、大赛主办方、平台运营方有权利进一步要求参赛者提交代码、解题思路等并基于此检视判断排行分数的合理性,从而对排名进行修正。各赛事赛题的最终排名应以各赛题所发布的公告或通知为准,线上排行榜仅为参考。参赛选手需要配合组委会对比赛作品的有效性与真实性进行验证。
- 晋级规则:赛段晋级名额、方式由各赛题设定。若有参赛者主动弃赛,晋级名次顺延。晋级名额中以个人身份参赛的则个人选手个人晋级,如个人从属于某团队,则该团队整体晋级。
- 公平竞技:参赛者禁止在指定考核技术能力的范围外,利用规则漏洞或技术漏洞等不良途径提高成绩排名,禁止在比赛中抄袭他人作品、交换答案、使用多个小号,经发现将取消比赛成绩并严肃处理。
- 组织声明:组委会保留对比赛规则进行调整修改的权利、比赛作弊行为的判定权利和处置权利、收回或拒绝授予影响组织及公平性的参赛团队奖项的权利。
- 竞赛数据:组委会参赛人员使用提供的数据进行指定赛道的模型训练工作,参赛人员不得将数据用于任何商业用途。若做科研使用,请注明数据来源于相关赛题的出题方;参赛人员不得对外以任何形式转载、发布赛题的训练集、验证集的全部或任意部分。
- 知识产权:参赛作品(包含但不限于结果文件、算法、模型、方案等)的相关权利由出题单位、参赛者、官方竞赛平台三方共享。
- 奖励分配:竞赛平台、赛题主办方等均不对物质奖励的分配方式予以负责,物质奖励将颁发给个人参赛者或团队指定的个人。证书等将根据个人参赛和团队参赛予以区分,授予个人或团队(列明个人姓名)

实名认证
请注意,2022 赛季起实名认证都将作为晋级或切榜后成绩有效的前提。
实名认证需通过点击系统右上角用户名处,进入「设定」界面操作。
在此界面请先确认姓名是否为真实姓名,若不是请修改,并点击页面最下方的保存按钮。之后点击「前往实名认证」
在实名认证页面,你需要填入自己的身份证号和手机号(请使用登记在你身份证名下的手机号)
若三者信息匹配即可完成实名认证。
实名认证失败的人工审核
如果你的手机未实名认证在你个人名下,或,你信息都正确却始终无法成功实名认证
请将以下信息完整发送至 it@aispacesh.com:
-
你的用户名
-
你的姓名
-
你的身份证号码
-
你的身份证正面照片或扫描件
邮件标题可写为:「实名认证申请人工审核」
由Datawhale社区支持提供的baseline版本,供选手参考使用
baseline的下载:请戳这里
讲解视频:
上集:赛题解析及数据解析
下集:解题思路及Baseline详解
更多请参考:https://datawhaler.feishu.cn/docx/HUhPdhrKfoDnJvx5Zwccb2XqnQf
A榜
Start: 四月 18, 2023, 8 a.m.
概述: A榜开启,至5月25日24点自动关闭。需实名认证才能使成绩生效。
B榜
Start: 五月 26, 2023, 午夜
概述: B榜将在5月26日0点开启,请注意仅72小时提交窗口,28日24点自动关闭。有效的A榜成绩,才能使B榜成绩生效。
终选答辩阶段
Start: 五月 29, 2023, 午夜
概述: B榜前20名有效团队提交PPT并经过选拔,最终10个团队/个人进入终选答辩
比赛结束
七月 31, 2023, 8 a.m.
请登陆来参加比赛
登入| # | 用户名 | 分数 |
|---|---|---|
| 1 | shihs | 100.000 |
| 2 | qqpprun | 99.830 |
| 3 | jy2211 | 99.830 |